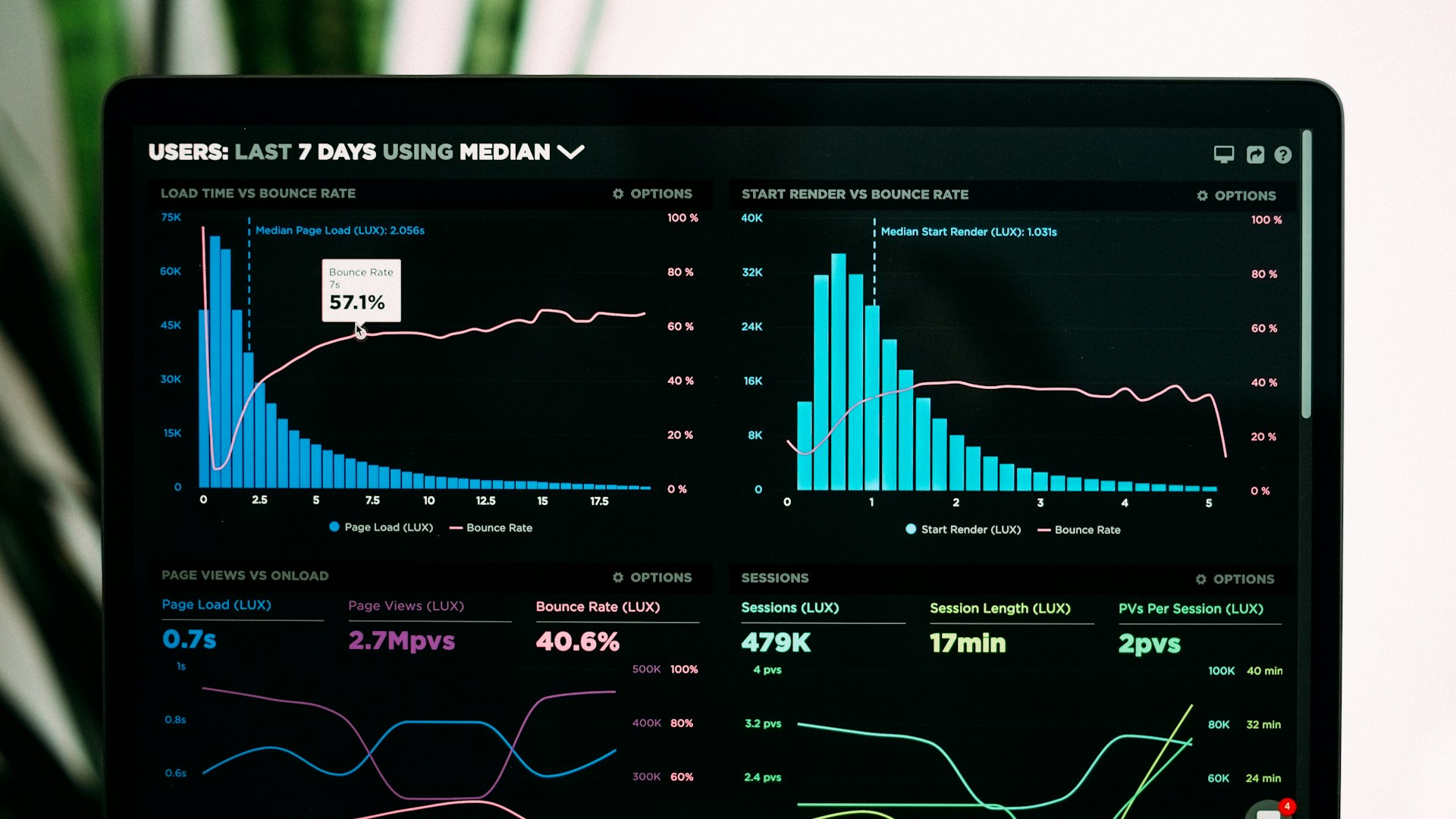
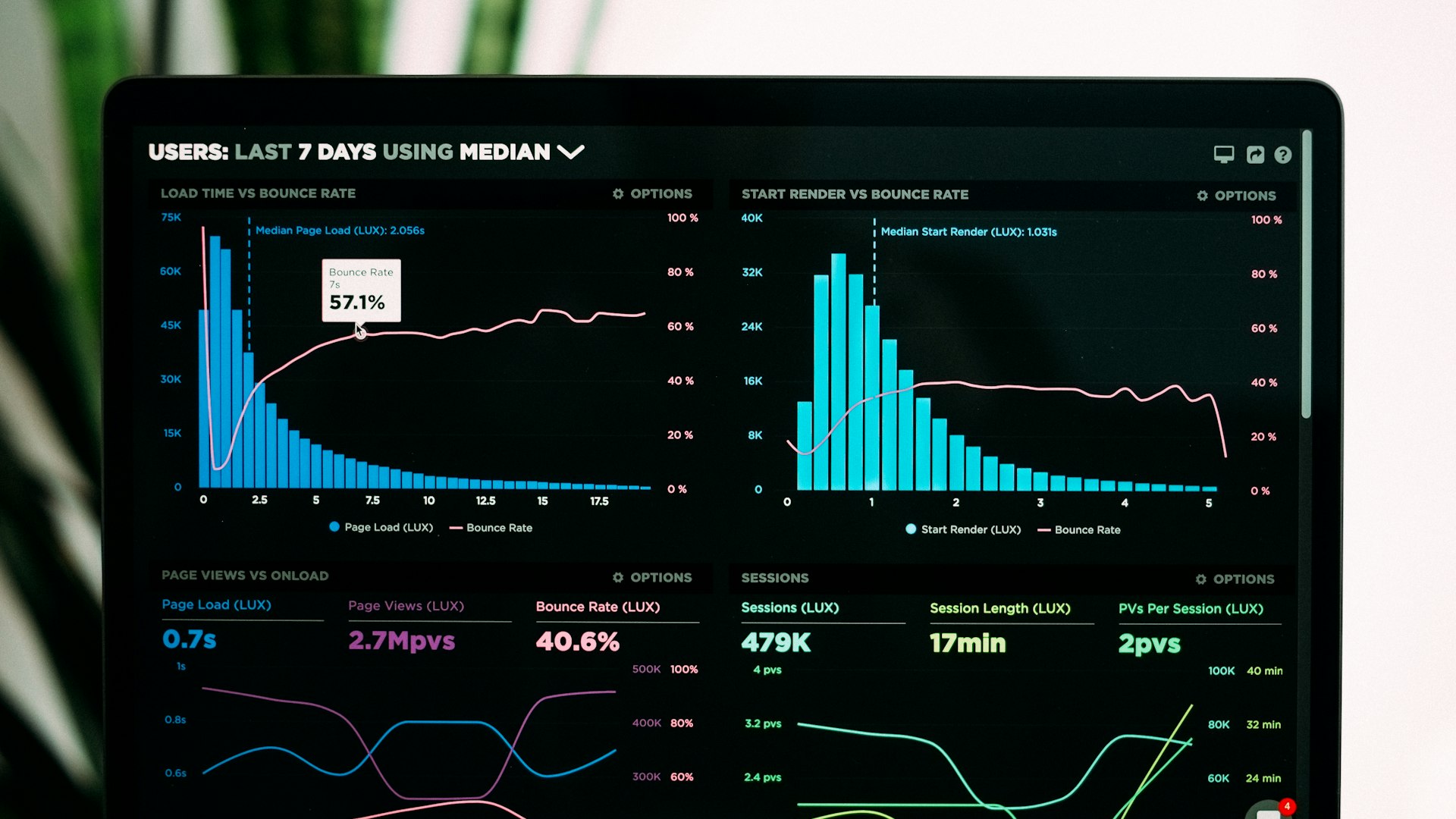
Most A/B tests we audit on client accounts produce results that look meaningful but aren't statistically valid. Sample too small, picked the winner too early, or tested two things at once. The "winning" variant might just be random variance.
Here are the four rules we run every SFMC A/B test by.
What SFMC lets you A/B test
- Subject line
- Preheader text
- From Name
- Email content (entire email, different variants)
- Send time
Pick one thing per test. Mixing breaks the experiment.
Rule 1: Sample size large enough
Rough floor: a few thousand subscribers per variant for open rate tests. Ideally 5-10% of audience per variant, with the remaining 80-90% receiving the winning variant after the test concludes.
Why: open rate movements of 2-3 percentage points are common from noise. To detect a true 5-point improvement with confidence, you need enough subscribers that noise averages out.
Audience of 2,000 total? A/B testing is probably not worth it. Audience of 100k+? Test confidently with 10% per variant.
Rule 2: One variable per test
If variant A has a different subject line and a different hero image, the winner tells you nothing about which change drove the difference. Was it the subject, or the image, or both?
One variable per test. Subject line this week, hero image next week. Slower, but each result is actionable.
Rule 3: Wait long enough for the winner call
Minimum 24 hours before selecting the winner. Ideally 48-72 hours for audiences spread across time zones.
Open rate after 2 hours is not representative - subscribers in other timezones haven't woken up. SFMC defaults to a short test window; override it.
Rule 4: Set the winning criterion before starting
Pick one metric - open rate, click rate, or conversion rate - before the test starts. Don't look at the numbers and pick whichever metric the variant you liked won on.
For brand/subject-line tests: click-through rate is more reliable than open rate since iOS 15's Mail Privacy Protection inflates opens.
For content tests: click-to-open rate or downstream conversion.
For send-time tests: open rate, but be aware iOS bias.
Configuring the test in SFMC
Email Studio > Create > A/B Test. Options:
- Test subject, preheader, from name, or content
- Audience percentage per variant (e.g., 10% A, 10% B, 80% winner)
- Winning metric (open, click, click-to-open)
- Test duration (at least 24 hours)
- Winner selection: automatic (SFMC picks) or manual (team reviews)
Start with manual winner selection until the team is comfortable with the interface; switch to automatic once trust is established.
Mistake 1: Sample too small
500 subscribers per variant, results 52% vs 54% open rate. Looks like B won - but the difference is within noise. Statistical significance requires bigger samples; 500 doesn't clear it.
Mistake 2: 2-hour winner selection
Team runs a test Monday at 9 AM, picks winner at 11 AM. Subscribers in Europe haven't opened yet. Selected winner might perform worse across the full audience.
Rule: no winner selection before 24 hours.
Mistake 3: Changing two variables
Variant A: new subject + new hero image. Variant B: old subject + old hero image. A wins - is it the subject or the hero? Unknown. Next test should change only one.
When A/B testing isn't worth it
Small audience (<5k total)? Detectable effects would need to be huge. Test less frequently, larger changes, and use your judgment.
Infrequent sends (monthly newsletter)? Each test takes a month to run. Consider carrying learnings across similar campaigns instead of re-testing each time.
Patterns that consistently matter
From aggregate client data, the tests that produce consistent lift:
- Personalization in subject (
%%FirstName%%) vs generic - typically 5-15% open lift - Urgency language ("Ends tonight") vs evergreen - 10-20% open lift for promotional
- Single CTA vs multiple - single CTA typically has higher CTR
- Button-style CTA vs text link - buttons outperform text links on mobile
These aren't universal - test in your audience. But they're good starting hypotheses.
Takeaway
A/B tests produce garbage without sample size, single-variable isolation, enough runtime, and a pre-declared metric. Get those four right and every test produces a learning; get any one wrong and the result tells you nothing. Treat A/B testing as a science, not a vibe check.
Running A/B tests on client SFMC accounts? Our Salesforce team designs statistically valid tests and synthesizes learnings across campaigns on production engagements. Get in touch ->
See our full platform services for the stack we cover.