- Client: Regional fintech operator (anonymized per agreement)
- Timeline: 10-month engagement (6-month build + 4-month fine-tuning & warranty)
- Team: 6 engineers including 2 from Sapota's data team, working under the AWS consulting partner who held the prime contract
- Outcome: Production data lake live at month 6, 3 additional data sources onboarded by the client through month 10, handover complete
How Sapota's data engineering team partnered with a regional AWS consulting firm to ship a Medallion data lake for a regulated fintech, from kick-off through go-live and into ongoing fine-tuning.
The client and the challenge
The client operates a regional file submission and reporting platform that licensed data providers use to submit structured records, and downstream consumers (banks, insurers, telcos, SMEs) use to query and pull processed data. The legacy stack worked but had aged: monolithic on-premise file processing, manual data quality checks, batch windows that bumped into each other when volume spiked, no proper analytics layer for product teams to build on top.
The brief was to rebuild the platform on AWS without disrupting the existing flow: same submission contracts for the dozens of data providers, same downstream consumers, the same business rules. New: a real data lake, real orchestration, real observability, real test coverage, and a compliance posture aligned with the regional banking regulator's technology risk framework.
The engagement ran under the prime contract of an AWS consulting partner. Sapota provided two data engineers embedded in the delivery team. This post anonymizes the client per agreement but keeps the architecture and execution detail intact.
Two accounts, one architecture
The platform spans two AWS accounts: a non-production account for development, SIT, and UAT environments, and a production account. Single sign-on via the client's IdP, role assumption for the engineering team, no static credentials anywhere.
This account boundary is the single most important decision on regulated workloads. It enforces blast radius (a stray Glue job cannot touch production data), simplifies the audit narrative, and lets the engineering team run continuous deploys against non-prod without governance friction. The production account is intentionally boring: Terraform-applied infrastructure only, no console click-ops, every change goes through GitLab CI/CD.
Medallion data lake on S3
The lake follows the Bronze / Silver / Gold pattern, one bucket family per environment (dev, SIT, UAT, prod, production). Bronze holds raw submitted files exactly as received from data providers, Silver holds cleansed and conformed records, Gold holds business-ready aggregates used by downstream APIs and analytics.
Bucket layout per environment:
*-landing: SFTP drop zone for incoming submissions, lifecycle policy archives after 90 days*-datalake: Bronze/Silver/Gold prefixes inside one bucket, separated by partition key*-file-share: outbound delivery for consumer organizations that pull processed files*-monitoring: Grafana artifacts, audit logs
Partitioning is by ingestion date and data provider ID. Athena queries on Gold against a 90-day window hit roughly 7 KB of data scanned per query because the partition pruning eliminates everything outside the window before the planner even reads the file footers. Cost discipline at the storage layer pays for itself the moment the first analyst writes a query without filters.
AWS Glue Visual ETL for the ingestion path
Every file submission flows through a Glue job that lands raw in Bronze, validates schema and key uniqueness, writes a clean copy to Silver, then triggers downstream transformations. Glue 5.0 on G.1X workers, 2 DPUs per job. About 68 Glue jobs live in the catalog at the end of Release #1.
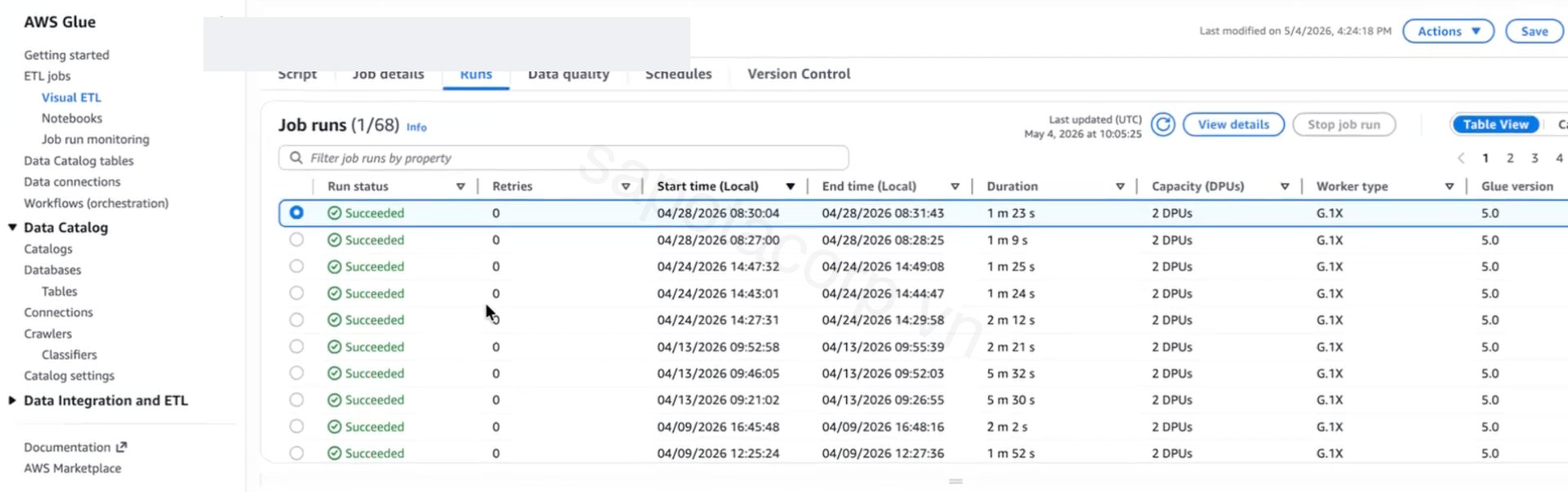
The job-level autoscaling story is worth calling out. Out of the box, Glue charges per DPU-hour with a 1-minute minimum per job. A naive setup with 10 DPUs per job for safety would have run the platform at roughly 3x the optimal cost. We baselined every job against its observed run profile, dropped most ingestion jobs to 2 DPUs (file sizes are predictable), reserved 10 DPUs only for the few transformation jobs that genuinely benefit from parallelism, and saved roughly 32% on Glue spend versus the initial estimate.
MWAA for orchestration
Apache Airflow (managed via MWAA) holds the workflow logic: when a file lands, what runs next, what triggers a reminder if a provider misses their submission window, how the daily scheduled jobs kick off, how the SIT-to-Gold promotion test runs.
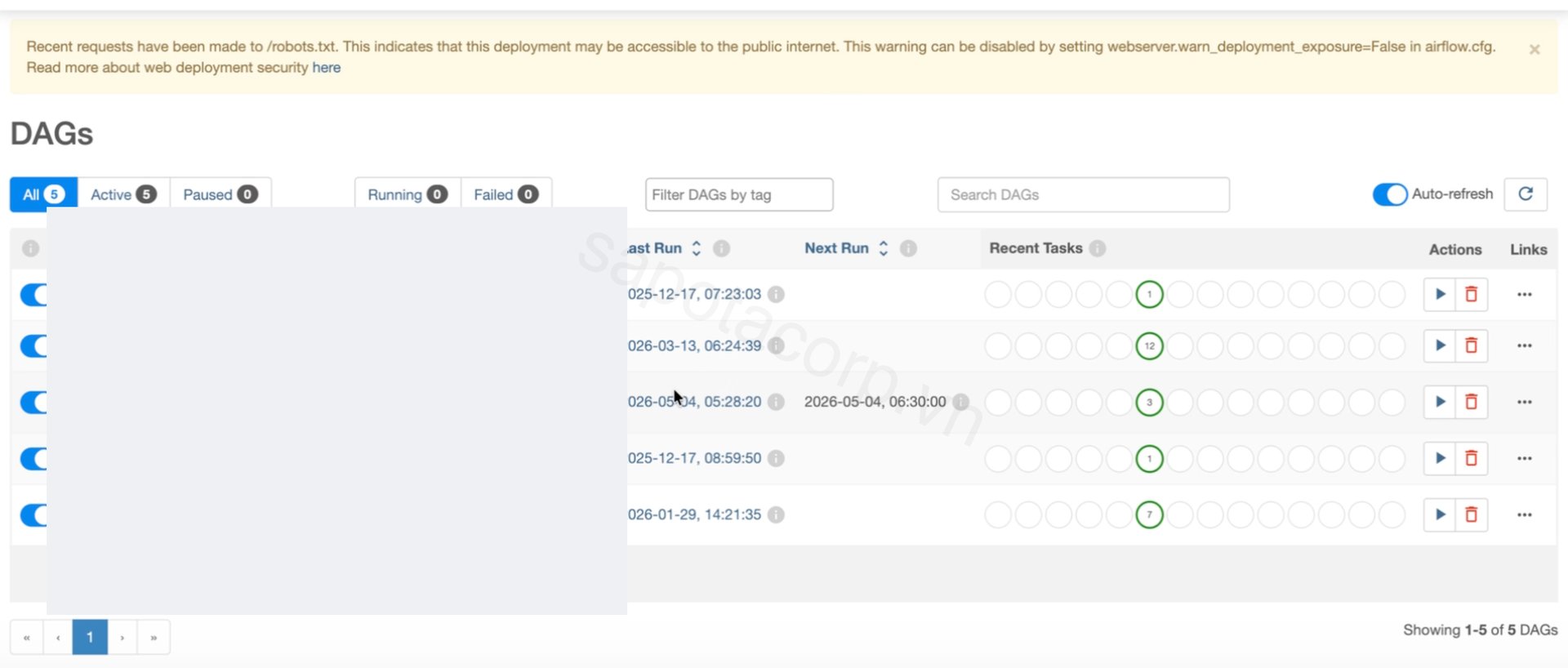
Keeping the DAG count small (5 production DAGs at Release #1) was a deliberate choice. The temptation on a Glue-heavy platform is to wire one DAG per pipeline. That fragments observability, makes pause-and-resume a per-pipeline operation, and makes it hard to reason about ordering when two flows touch the same Silver table. We consolidated by use case: ingestion DAG, scheduled reporting DAG, monitoring DAG. Each contains multiple Glue tasks but presents one mental model per operational concern.
Athena over Gold for product teams
Once data lands in Gold, product teams query through Athena. The catalog organizes by environment (dev_*, sit_*, uat_*, prod_*) and layer (*_bronze, *_silver, *_gold), with a separate *_system_glue schema for operational metadata (job runs, data quality results).
This naming convention is unglamorous and underrated. New engineers join the project and find their way around the lake without a tour because the schema names themselves communicate environment + layer. The audit team queries production_silver for a sample without anyone walking them through a Confluence page.
Data quality, baked in
The data quality framework runs as part of every Silver transformation. Schema conformance, null checks on required keys, uniqueness on the composite primary key, lookup integrity against reference tables. Failures land in a quarantine zone in Silver, fire a Grafana alert, and never reach Gold.
The UAT test plan formalized this. Every API contract had a test case structured as Pre-condition then Action then Verification, with the pre-condition usually a query against the underlying RDS or Silver schema to assert state, and the verification a query against Gold or the API response to confirm.
Twenty-eight test cases were enough to cover Release #1 because the platform's API surface is small and well-defined. The DQ rules engine carries most of the regression burden, not the test plan.
What 10 months actually looked like
A rough breakdown of where the time went:
- Weeks 1-3 (kick-off + discovery): AWS account provisioning, IAM and SSO setup, VPN configuration, security baseline, requirement gathering with the client's data team, documentation walk-throughs for the legacy file submission contracts.
- Months 1-3 (Release #1 MVP): Bronze landing pipeline, Silver transformation and DQ rules, the Custom Visual ETL pattern in Glue, MWAA setup, the first Athena queries against Silver. Internal SIT in late January, UAT with the client through February, sign-off at month 3.
- Months 3-6 (Release #2 Production): Gold aggregations for downstream consumers, the Data API layer over fixed-template responses, production deployment via Terraform, Grafana dashboards for operational visibility, cutover from legacy. Production go-live at month 6.
- Months 6-9 (Release #3 Fine Tuning): Workload tuning based on the first three months of real traffic (right-sized DPUs, partition strategy adjustments, query plan optimizations on the heaviest Athena queries), three additional data sources onboarded by the client team using the framework we left behind.
- Months 9-12 (Warranty + handover): Six-month managed support runs in parallel with the client team taking primary ownership. SOP documentation, runbooks for incident response, knowledge transfer sessions on the Custom Visual ETL pattern and the DQ rules engine. Project closure at month 12.
Roughly 40% of build time on ingestion + transformation, 25% on orchestration and monitoring, 15% on the Data API layer, 10% on infra-as-code and CI/CD, 10% on UAT, documentation, and handover material.
What the project delivered
- Production Medallion data lake on S3, partitioned and lifecycle-managed, scanning kilobytes per query on Gold
- 68 AWS Glue jobs for ingestion, cleansing, conformance, and Silver-to-Gold aggregation; Glue 5.0 on right-sized DPU configs
- 5 MWAA DAGs consolidating orchestration by operational concern, not by pipeline count
- Athena catalog organized by environment + layer with a separate operational metadata schema for self-service queries
- Grafana monitoring for pipeline health, SLA tracking, and DQ alerting; on-call gets paged on quarantine writes, not on Glue retries
- Terraform IaC for both AWS accounts, GitLab CI/CD for code + infra, no console click-ops in production
- Data API layer for fixed-template downstream consumers, deployed with the same release train
- Compliance posture mapped to the regional regulator's technology risk controls: encryption at rest + in transit, audit logging, segregation of duties via the two-account model, immutable Bronze for evidentiary purposes
- Ingestion framework the client engineering team has extended themselves: three additional data sources onboarded post-Release-1 without our involvement, using the documented Bronze landing pattern
What we would do again, and what we would not
Worth repeating on similar engagements:
- Two-account split from day one. Trying to retrofit the boundary later means a quarter of risk work that delivers zero feature value.
- Medallion layer naming in the Athena catalog. Self-documenting wins over wiki pages every time.
- DQ at Silver, not at Gold. Failing fast and quarantining keeps the consumer-facing layer trustworthy by default.
- DAG-per-concern over DAG-per-pipeline. The operational mental model stays small even as the job catalog grows.
Where we would push back next time:
- Glue 5.0 is fast, but the cold-start tax for small file ingestion is real. For sub-100KB files arriving frequently, a Lambda-based ingestion path would have been cheaper. We accepted the Glue cost for tool consolidation, and that was the right call here, but it's a tradeoff worth re-evaluating per project.
- MWAA is the most expensive piece of the platform per workload unit. For a future engagement at a smaller scale, EventBridge + Step Functions would cover the same orchestration needs at a fraction of the run rate.
If you are modernizing a regulated data platform
The AWS data engineering pattern that works for regulated workloads is not "lift the on-prem ETL into Glue." It is "rebuild around the storage layer as the system of record, with orchestration and compute as ephemeral consumers." That mental shift is what separates a 6-month modernization from a 2-year migration.
Sapota's data team has shipped this pattern across credit, e-commerce, and SaaS workloads in APAC. We embed inside a prime SI's delivery team when the client prefers a single contracting party, or we run the engagement directly when the client wants a focused vendor. We have an opinionated reference architecture for Medallion-on-S3 with Glue + MWAA + Athena that gets the first ingestion path live within two weeks of kick-off.
Reach out via the custom software page with a description of the platform you are modernizing and what the regulatory bar looks like. The first conversation usually clarifies whether the pattern fits within thirty minutes.





 Retool
Retool

